(本文作者为 wiwi,钛媒体经授权发布)
文 | wiwi
AI 圈又开始制造新名词了。
过去半个月,一个叫做 Loop Engineering 的概念突然在开发者和 AI 圈层中扩散。直译过来,它可以叫“循环工程”或“闭环工程”,但这两个中文词都不太准确。因为它真正引发争议的地方,并不是提出了一套全新的技术架构,而是用一个新名字,把 AI Coding 发展到今天的一个深层矛盾重新摆到了台前:
AI 已经让个人写代码更快,但还没有真正让组织交付变得更稳定。
过去两年,AI 编程工具最动人的叙事,是个人效率的跃迁。Copilot 帮你补全代码,Cursor 帮你理解项目,Claude Code 帮你改文件,Codex 帮你处理任务。一个开发者借助 AI 一天写出更多代码,一个周末做出一个产品,一个人完成过去需要几个人协作的原型,这些故事足够振奋,也足够适合传播。
但当 AI Coding 从个人工作台进入公司研发体系,问题很快变得复杂。
企业真正关心的,不只是代码生成速度,而是交付链路是否可控,风险是否可追溯,权限是否清晰,知识是否沉淀,成本是否可预算。一名工程师用 AI 提效 30%,并不必然意味着整个团队交付效率提升 30%。很多时候,更多代码反而带来了更重的 Review 压力,更快的原型反而制造了更多维护成本,更强的 Agent 反而暴露了更混乱的流程。
Loop Engineering 正是在这个背景下被推到台前。
它看似是在讨论一种新的 Agent 使用方式,实质上是在讨论一个更大的问题:当 Agent 已经具备持续循环执行任务的能力之后,组织是否有能力、也是否有意愿,重新设计自己的生产流程。
它没有发明“循环”
Loop Engineering 的导火索,是 OpenClaw 创始人 Peter Steinberger 的一句判断:你不应该继续给编码 Agent 写提示词了,你应该设计循环,让循环去提示你的 Agent。随后,Google Chrome 团队工程领袖 Addy Osmani 写下《Loop Engineering》,进一步将这个概念系统化。他将 Loop Engineering 概括为:不再由人持续提示 Agent,而是设计一个系统替人去提示 Agent。
这句话之所以容易传播,是因为它几乎是在宣判 Prompt Engineering 的退场。过去,提示词是人与 AI 协作的基本界面。用户提出需求,模型给出结果;开发者描述问题,Agent 修改代码;测试失败,人再把报错复制回去,让模型继续修。提示词在很长一段时间里,被视为 AI 应用层最重要的操作技能。
但这种工作方式有一个天然上限:人必须一直坐在驾驶位上。
Agent 每前进一步,都需要人给下一条指令;上下文变化了,需要人重新整理;测试失败了,需要人判断下一步;任务跑偏了,需要人停下来纠偏。表面上看 AI 在执行,实际上真正驱动工作流的仍然是人。
Loop Engineering 试图改变这种关系。它不再把提示词视为中心,而是把提示词嵌入一套持续运行的外部系统:任务如何触发,Agent 如何获取上下文,能调用哪些工具,在哪些环节必须停下来,失败后如何恢复,结果如何验收,经验如何沉淀到下一次执行中。
但这里必须先讲清楚一个容易被过度包装的问题:Loop Engineering 并没有发明“循环”。
早在 ReAct 框架里,Agent 就已经可以通过“推理—行动—观察”的方式与外部环境持续交互。ReAct 的核心不是单纯的内部推理,而是让模型在 reasoning traces 与 task-specific actions 之间交替运行;actions 本身就允许模型连接外部来源或环境,获取新的信息,再根据观察结果继续调整下一步行动。
也就是说,一个设计良好的 ReAct Agent,本来就可以读取日志、调用工具、运行测试、观察失败结果,并进入下一轮修复。它并不需要等到 Loop Engineering 这个新词出现,才具备“持续行动—观察—修正”的能力。
因此,如果把 Loop Engineering 说成是 ReAct 之后出现的全新循环架构,技术上并不严谨。它更像是对既有 Agent 能力的一次工程化、产品化和组织化再包装。
这也是它引发争议的根本原因:一方面,它确实像旧概念换皮;另一方面,它又确实击中了一个新阶段的问题。
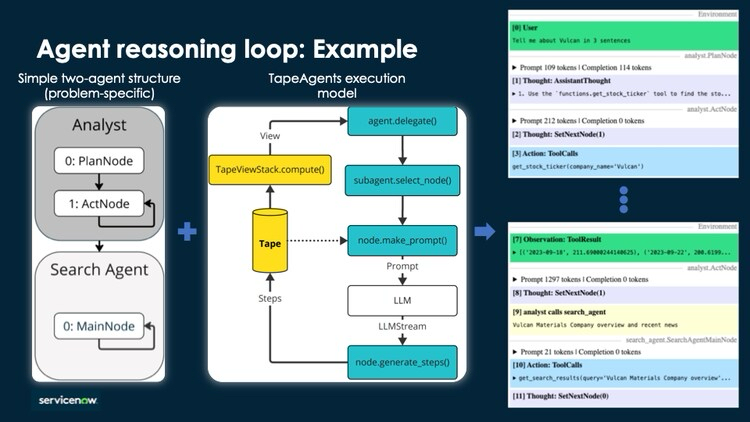
Agent Reasoning Loop
新意不在技术,而在生产组织
Loop Engineering 真正的新意,不在于 Agent 会不会循环,而在于这个循环被放进了真实生产系统之后,会触发一系列过去单个 Agent 框架无法独立回答的问题。
任务由谁触发?权限由谁授予?哪些系统可以连接?哪些动作必须人工确认?什么时候停止?失败以后如何回滚?结果由谁验收?事故由谁负责?
这些问题不属于某一个 Agent 框架的内部逻辑,而属于生产级 Agent 系统的工程化与组织治理。
Addy Osmani 在文章中将 Loop Engineering 拆成了自动化触发、工作区隔离、Skills、连接器、子 Agent 等组件。单独看这些组件,也都不新。自动化触发像事件驱动和工作流,工作区隔离像 Git 分支和 worktree,Skills 像团队规范、Runbook 和知识库,连接器像 API 集成和 MCP,子 Agent 像多角色协作,外部记忆像状态机、日志和事件记录。
所以,那些吐槽“这不就是几个 Agent 加状态机吗”的人,并不完全错。
但科技行业的新概念之所以能够传播,往往不取决于它在技术上有多原创,而取决于它是否准确命中了某个阶段的共同焦虑。Loop Engineering 的价值就在这里:它把过去分散在 DevOps、自动化、Agent 架构、知识管理和组织流程中的实践,重新放到了 AI Coding 的语境下,并给出了一个更容易传播的框架。
更准确地说,Loop Engineering 不是技术革命,而是一个阶段性标签。
它标记的是 AI Coding 的重心正在外移:从“模型如何回答”转向“系统如何持续驱动模型”;从“一个 Agent 能否完成任务”转向“一个组织能否承受 Agent 持续完成任务”。
这才是它真正值得讨论的地方。
Bug 修复案例说明的不是新技术,而是新冲突
一个典型的软件团队场景,可以说明 Loop Engineering 的真实矛盾。
在传统研发团队里,一个线上 Bug 往往是这样流转的:客服在群里反馈用户打不开页面,测试先判断是不是操作问题,产品补充业务背景,研发查日志并定位代码,修复后交给测试验证,最后上线。复杂一点的问题,还会被转成工单,进入排期。
这条链路看起来普通,但里面包含大量隐性判断。它是不是 Bug?影响范围有多大?是否涉及支付、订单、账户等高风险模块?能不能直接修?谁有权限上线?失败以后谁兜底?同类问题之前有没有发生过?
过去,这些判断散落在人的经验里。一个老研发、一个熟悉业务的测试、一个反应快的产品经理,靠经验和默契把流程跑起来。
现在,如果将 Agent 接入这条链路,事情会变成另一种样子。客服群出现“支付失败”“页面打不开”“按钮点不动”等关键词后,Agent 自动监听并创建任务;它连接日志系统、订单系统、代码仓库和工单系统,收集上下文并判断风险等级;低风险前端 Bug 可以在独立分支里修复、运行测试并生成变更说明;涉及支付、权限、数据写入等高风险模块,则自动停止并转交人工确认;上线后,它再将处理结果同步回业务侧,并把经验沉淀为新的规则或 Skill。
这个例子经常被用来说明 Loop Engineering 的价值。但更严格地说,它并不能证明 Loop Engineering 拥有 ReAct 做不到的新能力。一个设计良好的 ReAct Agent,同样可以连接日志系统、修改代码、运行测试、观察失败结果,并进入下一轮修复。
真正的问题不在于它能不能循环,而在于当这个循环被接入客服群、工单系统、代码仓库和上线流程之后,组织是否允许它自动判断、自动推进、自动提交,甚至自动改变他人的工作边界。
技术循环不是难点,组织授权才是难点。
这也是 Loop Engineering 最值得讨论的地方。它没有把 Agent 变成一个全新的物种,却把 Agent 的持续行动能力,推到了组织流程、权限边界和责任分配面前。
AI Coding 的红利,正在从个人提效进入组织适配
Loop Engineering 之所以会在这个时间点火起来,是因为 AI Coding 正在从第一阶段进入第二阶段。
第一阶段是个人提效。AI 编程工具解决的是“一个开发者能不能更快完成任务”。这个阶段的典型场景,是代码补全、文件修改、单点重构、测试生成、项目解释。独立开发者和小团队最容易从中受益,因为他们缺人、缺时间、缺配套角色,AI 可以迅速补足能力缺口。
第二阶段是组织适配。企业真正要解决的问题,不是某个工程师能否更快写代码,而是一个研发组织能否在引入 AI 后保持稳定交付。这里的关键词不再是代码速度,而是流程控制、权限边界、质量标准、知识沉淀和成本治理。
这也是很多团队在引入 AI Coding 后遇到的尴尬:个人效率确实提高了,但团队整体效率没有等比提升。开发者产出的代码更多了,Review 压力却更大;需求推进速度变快了,上下文丢失也更严重;原型越来越多,但真正可维护、可上线、可复盘的东西并没有同步增加。
原因很简单。软件研发从来不是一个纯粹的代码生产问题,而是一个组织协作问题。代码只是结果,真正决定交付质量的是需求如何进入、任务如何拆分、上下文如何传递、风险如何识别、结果如何验收、问题如何复盘。
Loop Engineering 的火,恰恰说明行业已经意识到:继续讨论“怎么写 Prompt”不够了。团队需要的不是一个更会聊天的 AI 助手,而是一套能把 Agent 纳入研发秩序的机制。
它看似是技术概念,实际上更像管理概念。它说的不是“让模型更聪明”,而是“让工作流更可控”。
流程不是中性的,背后是权力分配
Loop Engineering 的乐观叙事,是把隐性流程显性化,把人工兜底变成系统循环。这听起来很合理,也符合技术行业一贯的效率想象。但在真实组织中,流程从来不是中性的。
一个客服 Bug 从群里冒出来,到最终被修复上线,表面上是一条信息链路,背后却是一套权力和责任的分配方式。谁有权判断这是 Bug 还是需求?谁决定优先级?谁能推动研发插单?谁为线上事故背锅?谁在日报里呈现自己的工作量?这些细节共同构成了组织运行的真实秩序。
Loop Engineering 触碰的正是这套秩序。
如果一个 Agent 可以自动监听客服群、判断问题类型、创建工单、分配任务、修改代码、运行测试、生成 Review,再把结果同步回业务侧,那么测试主管、一线研发、产品经理、项目经理、运维同学的权责边界都会被重新切分。
这不是简单的“效率提升”。
对部分岗位来说,Agent 循环不是工具,而是对流程控制权的重新分配。过去,一个问题能不能进入研发排期,可能取决于产品经理的判断;一个 Bug 是否严重,可能取决于测试负责人的经验;一个线上问题要不要当天修,可能取决于研发负责人的资源协调。Loop 一旦把这些判断显性化、规则化、自动化,就等于把一部分灰色地带从人的手里拿走。

因此,Loop Engineering 最大的阻力未必来自技术部门,而可能来自组织内部的既得利益。
很多公司并不是不知道流程混乱,而是依赖这种混乱维持权力弹性。模糊的流程可以让人临时插单,可以让责任被转移,可以让一些岗位通过“协调”“推进”“沟通”来证明自身价值。一旦 Agent 把流程写成明确的触发条件、检查点和停止规则,很多原本靠经验、关系和话语权维系的空间都会被压缩。
这也是为什么 Loop Engineering 在个人开发者和小团队里听起来很兴奋,在大组织里却可能变得异常沉重。小团队的问题是缺人,所以愿意让 Agent 补位;大组织的问题是人太多、边界太复杂,所以每一次自动化都会牵动岗位权力。
AI 进入组织,从来不是简单的工具升级,而是权力结构的再分配。谁定义流程,谁就定义工作。谁定义 Agent 的循环,谁就开始定义组织未来的生产秩序。

被低估的前置成本:流程再造
Loop Engineering 常常被包装成一种轻巧的方法论:设计一个循环,让 Agent 持续工作。但真正落到企业里,它的前置工程远比想象中复杂。
要让 Agent 自动处理客服 Bug,组织首先要回答一系列基础问题。客服反馈格式是否统一,Bug 分类标准是否明确,日志系统能否稳定访问,代码仓库权限如何控制,测试用例是否足够完整,哪些模块允许自动修复,哪些改动必须人工确认,上线流程是否支持灰度和回滚,事故责任如何追溯,每一次循环的成本如何统计。
这些问题如果没有答案,Agent 不是提效工具,而是把原本混乱的流程跑得更快。
这意味着,Loop Engineering 的成功前提不是购买一个更强的 AI Coding 工具,而是先完成一次隐性的业务流程再造。它不是把纸质流程搬到线上,也不是给每个环节加一个 AI 助手,而是重新定义流程本身:哪些环节应该存在,哪些决策可以自动化,哪些节点必须保留人类判断,哪些责任必须重新划分。
这件事的成本,远高于引入一个 AI 工具。
很多企业想象中的 Loop Engineering,是在现有流程之上挂一个 Agent,让它帮忙跑腿。但真实情况往往是,Agent 一接入,流程里的脏东西就全部暴露出来:命名不统一、接口不稳定、权限混乱、文档过期、测试缺失、业务规则靠人记、上线规范靠口头传递。
此时,Loop 不是解决问题,而是在逼组织承认:过去所谓的流程,很多只是熟人协作和人工兜底。
这会导致明显分化。对于流程已经高度结构化的团队,Loop Engineering 可能成为效率放大器。代码仓库规范清晰、CI/CD 完整、测试体系成熟、工单流转稳定、权限边界明确的团队,确实可以让 Agent 接管一部分低风险、重复性任务。
但对于流程治理能力薄弱的团队,它反而会变成昂贵的咨询项目。你以为自己在做 AI 自动化,最后发现真正要补的是组织管理、知识库、权限体系、质量标准和发布流程。
Loop Engineering 的门槛,不在 Loop,而在 Engineering。它要求组织具备把隐性经验写成规则、把模糊责任切成边界、把临时协作变成系统流程的能力。而这恰恰是多数公司的短板。
成本和风险,从单次调用变成持续运行
Loop Engineering 还有一个容易被低估的问题:当 Agent 从被动响应变成持续循环,AI 的成本和风险也会同步改变。
Prompt 时代,人每问一次,模型回答一次。成本大致可感知,风险也相对可控。Loop 时代,Agent 会自己拆任务、调用工具、验证结果、反复重试,甚至调用另一个 Agent 来 Review 自己的输出。效率被放大的同时,token 消耗、工具调用和错误传播也会被放大。
Business Insider 在报道中也提到,loop engineering 虽然可以让 Claude Code、Codex 这类工具持续推进任务,但多 Agent 和多轮循环会带来更高的 token 消耗,用户需要谨慎设计循环和成本结构。
一个看似简单的任务,如果在循环中反复读取上下文、调用模型、运行测试、生成 diff、再让子 Agent Review,成本可能迅速膨胀。对大公司来说,这可能只是预算问题;对独立开发者和小团队来说,这可能直接决定产品能不能活下去。
更大的问题是责任。
当 Agent 自动修改代码、自动调用系统、自动触发流程时,谁来为错误负责?如果它误判了一个高风险问题,把不该上线的代码上线了,责任在设计 Loop 的人,还是执行任务的 Agent,还是批准这套流程的管理者?
这不是哲学问题,而是工程问题。
真正成熟的 Loop Engineering,一定不是让 Agent 放飞自我,而是通过更严格的边界,让 Agent 在可控范围内自主运行。好的 Loop 应该像一条有护栏的自动化产线,而不是一个拿着 root 权限到处乱跑的实习生。
它需要预算上限、权限分级、人工确认点、回滚机制、审计日志、异常熔断和明确的停止条件。否则,Loop Engineering 不是效率革命,而是事故放大器。
新岗位:AI 产线设计师
如果 Loop Engineering 继续发展,它真正催生的新角色,可能不是更会写 Prompt 的工程师,也不是单纯的 Agent 产品经理,而是一类更接近“AI 产线设计师”的岗位。
这个角色的核心工作,不是亲手写每一行代码,而是设计一条能让 Agent 稳定生产代码、文档、测试、报告和运营动作的数字流水线。
它要定义标准作业程序,决定什么任务可以进入循环,什么任务必须拦截;要设计检查点,规定在哪一步跑测试,在哪一步做 Review,在哪一步需要人工确认;要配置异常处理,决定 Agent 卡住怎么办,成本超标怎么办,权限越界怎么办,结果不可信怎么办;还要维护 Skills,把团队的经验、规范、偏好和禁区沉淀成可被 Agent 调用的知识模块。
这听起来不像传统工程师,更像数字流水线的工头。
工业时代的工头不一定亲手拧每一颗螺丝,但他必须知道产线如何运转,哪里容易卡住,哪个环节必须质检,什么情况要停线。AI 时代的“工头”也类似:他不一定亲自完成所有代码实现,但必须懂系统、懂业务、懂流程、懂风险,还要能把人的经验翻译成机器可执行的循环。
这会改变工程师的价值排序。过去,高价值工程师的核心能力是写复杂代码、解决复杂 Bug、理解复杂系统。未来,这些能力仍然重要,但会被进一步抽象。谁能设计更稳定的 Agent 工作流,谁能把团队经验沉淀成可复用的循环,谁能让 AI 在可控边界内持续产出,谁就会获得新的组织议价权。
这类人既不像传统研发,也不像项目经理,更不像测试或运维。他们可能介于工程负责人、流程架构师、AI 产品经理和自动化平台负责人之间。
更重要的是,这类岗位的薪酬和管理方式,也会和今天的工程师不同。因为他们交付的不是某个具体功能,而是一套生产能力;他们优化的不是单个任务耗时,而是整个组织的吞吐率;他们管理的不是几个人,而是一群可以 24 小时运行、不断消耗 token、不断调用工具、不断产生结果和风险的 Agent。
Loop Engineering 表面上讨论的是 AI 如何写代码,深层改变的却是“谁来定义工作”的权力结构。
它不是技术革命,而是组织压力测试
所以,Loop Engineering 到底是真革命,还是炒冷饭?
如果从技术独创性看,它确实没有那么新。它没有发明 Agent 循环,也没有提供 ReAct 做不到的根本能力。自动化、状态机、DevOps、Agent 编排、MCP、Skills、工作区隔离、多角色协作,这些东西早就存在。它更像是把旧组件重新排列组合,然后放进 AI Coding 的新语境里。
所以,认为它只是“几个 Agent 加状态机”的批评,并非完全错误。
但如果从组织影响看,它又不只是炒冷饭。
因为它真正挑战的,不是 ReAct,也不是 Prompt Engineering,而是过去那套低透明度、强人工兜底、靠经验和关系维持的软件生产秩序。
过去,团队靠群聊、会议、熟人协作和人工兜底,把一个个需求推过终点。未来,越来越多可重复的环节会被写成循环,让 Agent 在其中承担执行、检查、记录和反馈的角色。
但循环能不能跑起来,取决于组织愿不愿意把自己拆开。拆开流程,拆开权力,拆开责任,拆开那些长期被模糊处理的灰色地带。
这才是 Loop Engineering 背后的现实阻力。很多公司会高估 Agent 的能力,低估流程改造的成本;很多管理者会期待 AI 提效,却不愿意重新划分权责;很多团队会购买 AI 工具,却没有能力把隐性经验变成可执行规则;很多工程师会担心岗位被替代,但真正发生的可能是岗位权力被重新切分。
因此,Loop Engineering 最终考验的不是 AI 工具,而是组织成熟度。
成熟组织会把它变成生产力。混乱组织会把它变成事故源。权责不清的组织,会先在内部阻力中打转。
结语:真正被挑战的,是人工兜底的旧秩序
AI 圈的新词还会继续出现。它们有些会变成泡沫,有些会留下来成为方法论。Loop Engineering 最终会不会成为一个长期概念,现在还不好说。
但它至少说对了一件事:AI 不是接入工具就结束了。真正困难的,是让工具进入循环。而循环一旦开始,组织本身就必须被重新设计。
所以,与其说 Loop Engineering 要取代 Prompt Engineering,不如说它真正挑战的是过去那套混乱的软件协作方式。
提示词不会死。ReAct 也没有过时。它们只是被放进了更复杂的生产环境里。
真正可能被淘汰的,是那种以为“买一个 AI 工具,就能绕过组织治理”的天真想象。
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或者下载钛媒体App
本文为本站原创内容,如需转载请注明出处。
本文永久地址:https://m.ace6232.cn/article/42940.html
文章观点仅供学习交流参考。